
Go语言中 Channel & Panic 实现原理
Posted on April 18, 2019 • 4 minutes • 761 words
Table of contents
Channel和Panic算是Go语言中比较重要的特性,体现了Go语言的设计思想。这也让Channel和Panic的原理成为面试中常见的问题之一
autoauto- [1. Channel](#1-channel)auto - [1.1. channel实现原理](#11-channel实现原理)auto - [1.1.1. chan数据结构](#111-chan数据结构)auto - [1.1.2. 环形队列](#112-环形队列)auto - [1.1.3. 等待队列](#113-等待队列)auto - [1.1.4. 类型信息](#114-类型信息)auto - [1.1.5. 锁](#115-锁)auto - [1.2. chan读写](#12-chan读写)auto - [1.2.1. 创建channel](#121-创建channel)auto - [1.2.2. 向channel写数据](#122-向channel写数据)auto - [1.2.3. 从channel读数据](#123-从channel读数据)auto - [1.2.4. 关闭channel](#124-关闭channel)auto- [2. panic](#2-panic)auto - [2.1. 数据结构](#21-数据结构)auto - [2.2. 崩溃](#22-崩溃)auto - [2.3. 恢复](#23-恢复)auto - [2.4. 总结](#24-总结)autoauto1. Channel
1.1. channel实现原理
1.1.1. chan数据结构
src/runtime/chan.go:hchan定义了channel的数据结构:
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写
}
从数据结构可以看出channel由队列、类型信息、goroutine等待队列组成,下面分别说明其原理。
1.1.2. 环形队列
chan内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的。
下图展示了一个可缓存6个元素的channel示意图:
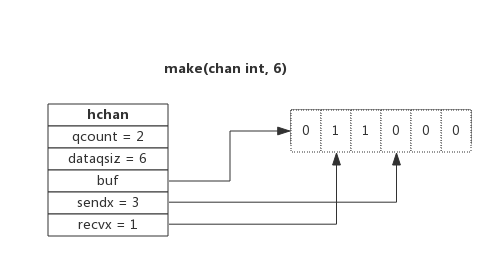
- dataqsiz指示了队列长度为6,即可缓存6个元素;
- buf指向队列的内存,队列中还剩余两个元素;
- qcount表示队列中还有两个元素;
- sendx指示后续写入的数据存储的位置,取值[0, 6);
- recvx指示从该位置读取数据, 取值[0, 6);
1.1.3. 等待队列
从channel读数据,如果channel缓冲区为空或者没有缓冲区,当前goroutine会被阻塞。
向channel写数据,如果channel缓冲区已满或者没有缓冲区,当前goroutine会被阻塞。
被阻塞的goroutine将会挂在channel的等待队列中:
- 因读阻塞的goroutine会被向channel写入数据的goroutine唤醒;
- 因写阻塞的goroutine会被从channel读数据的goroutine唤醒;
下图展示了一个没有缓冲区的channel,有几个goroutine阻塞等待读数据:
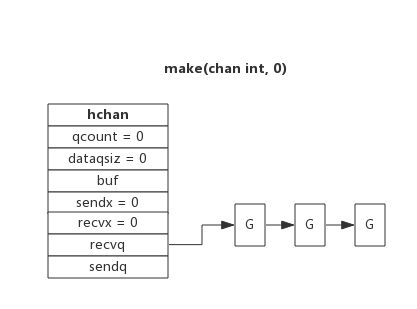
注意,一般情况下recvq和sendq至少有一个为空。只有一个例外,那就是同一个goroutine使用select语句向channel一边写数据,一边读数据。
1.1.4. 类型信息
一个channel只能传递一种类型的值,类型信息存储在hchan数据结构中。
- elemtype代表类型,用于数据传递过程中的赋值;
- elemsize代表类型大小,用于在buf中定位元素位置。
1.1.5. 锁
一个channel同时仅允许被一个goroutine读写,为简单起见,本章后续部分说明读写过程时不再涉及加锁和解锁。
1.2. chan读写
1.2.1. 创建channel
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。
创建channel的伪代码如下所示:
func
makechan
(t *chantype, size
int
)
*hchan
{
var c *hchan
c =
new
(hchan)
c.buf =
malloc
(元素类型大小*size)
c.elemsize = 元素类型大小
c.elemtype = 元素类型
c.dataqsiz = size
return
c
}
1.2.2. 向channel写数据
向一个channel中写数据简单过程如下:
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒;
简单流程图如下: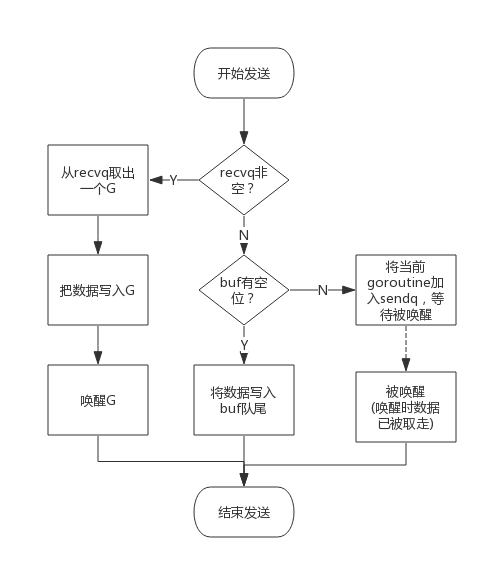
1.2.3. 从channel读数据
从一个channel读数据简单过程如下:
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
简单流程图如下: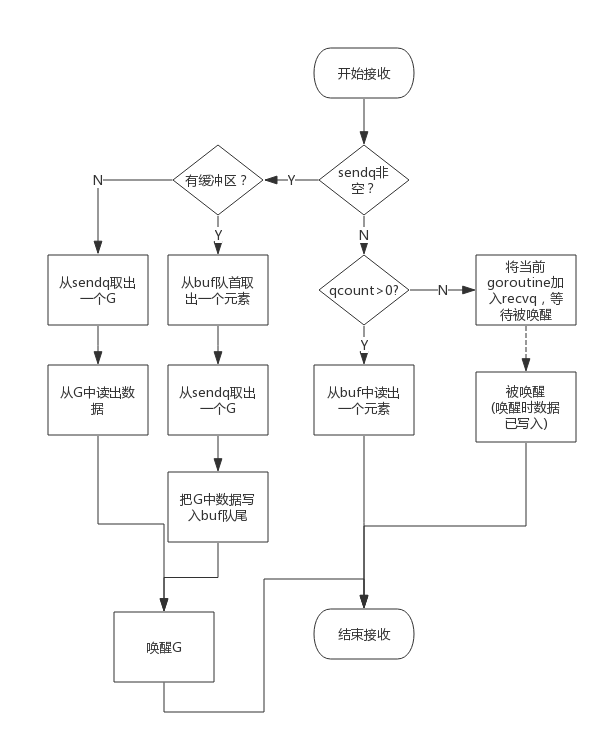
1.2.4. 关闭channel
关闭channel时会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic。
除此之外,panic出现的常见场景还有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
2. panic
panic和recover关键字会在编译期间
被 Go 语言的编译器转换成OPANIC和ORECOVER类型的节点并进一步转换成gopanic和gorecover两个运行时的函数调用。
2.1. 数据结构
panic在 Golang 中其实是由一个数据结构表示的,每当我们调用一次panic函数都会创建一个如下所示的数据结构存储相关的信息:
type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
}
argp 是指向 defer 调用时参数的指针;
arg 是调用 panic 时传入的参数;
link 指向了更早调用的 _panic 结构;
recovered 表示当前 _panic 是否被 recover 恢复;
aborted 表示当前的 panic 是否被强行终止;
从数据结构中的link字段我们就可以推测出以下的结论 —panic函数可以被连续多次调用,它们之间通过link的关联形成一个链表。
2.2. 崩溃
首先了解一下没有被recover的panic函数是如何终止整个程序的,我们来看一下gopanic函数的实现
func gopanic(e interface{}) {
gp := getg()
// ...
var p _panic
p.arg = e
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
d := gp._defer
if d == nil {
break
}
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
p.argp = unsafe.Pointer(getargp(0))
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
p.argp = nil
d._panic = nil
d.fn = nil
gp._defer = d.link
pc := d.pc
sp := unsafe.Pointer(d.sp)
freedefer(d)
if p.recovered {
// ...
}
}
fatalpanic(gp._panic)
*(*int)(nil) = 0
}
我们暂时省略了 recover 相关的代码,省略后的 gopanic 函数执行过程包含以下几个步骤:
获取当前 panic 调用所在的 Goroutine 协程;
创建并初始化一个 _panic 结构体;
从当前 Goroutine 中的链表获取一个 _defer 结构体;
如果当前 _defer 存在,调用 reflectcall 执行 _defer 中的代码;
将下一位的 _defer 结构设置到 Goroutine 上并回到 3;
调用 fatalpanic 中止整个程序;
fatalpanic 函数在中止整个程序之前可能就会通过 printpanics 打印出全部的 panic 消息以及调用时传入的参数:
func fatalpanic(msgs *_panic) {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
var docrash bool
systemstack(func() {
if startpanic_m(); & &msgs != nil {
atomic.Xadd(&runningPanicDefers, -1)
printpanics(msgs)
}
docrash = dopanic_m(gp, pc, sp)
})
if docrash {
crash()
}
systemstack(func() {
exit(2)
})
*(*int)(nil) = 0 // not reached
}
在fatalpanic函数的最后会通过exit退出当前程序并返回错误码2,不同的操作系统其实对exit函数有着不同的实现,其实最终都执行了exit系统调用来退出程序。
2.3. 恢复
到了这里我们已经掌握了panic退出程序的过程,但是一个panic的程序也可能会被defer中的关键字recover恢复,在这时我们就回到recover关键字对应函数gorecover的实现了:
func gorecover(argp uintptr) interface{} {
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
这个函数的实现其实非常简单,它其实就是会修改panic结构体的recovered字段,当前函数的调用其实都发生在gopanic期间,我们重新回顾一下这段方法的实现:
func gopanic(e interface{}) {
// ...
for {
// reflectcall
pc := d.pc
sp := unsafe.Pointer(d.sp)
// ...
if p.recovered {
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
fatalpanic(gp._panic)
*(*int)(nil) = 0
}
上述这段代码其实从_defer结构体中取出了程序计数器pc和栈指针sp并调用recovery方法进行调度,调度之前会准备好sp、pc以及函数的返回值:
func recovery(gp *g) {
sp := gp.sigcode0
pc := gp.sigcode1
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched)
}
在defer
一节中我们曾经介绍过deferproc的实现,作为创建并初始化_defer结构体的函数,它会将deferproc函数开始位置对应的栈指针sp和程序计数器pc存储到_defer结构体中,这里的gogo函数其实就会跳回deferproc:
TEXT runtime·gogo(SB), NOSPLIT, $8-4
MOVL buf+0(FP), BX // gobuf
MOVL gobuf_g(BX), DX
MOVL 0(DX), CX // make sure g != nil
get_tls(CX)
MOVL DX, g(CX)
MOVL gobuf_sp(BX), SP // restore SP
MOVL gobuf_ret(BX), AX
MOVL gobuf_ctxt(BX), DX
MOVL $0, gobuf_sp(BX) // clear to help garbage collector
MOVL $0, gobuf_ret(BX)
MOVL $0, gobuf_ctxt(BX)
MOVL gobuf_pc(BX), BX
JMP BX
这里的调度其实会将deferproc函数的返回值设置成1,在这时编译器生成的代码就会帮助我们直接跳转到调用方函数return之前并进入deferreturn的执行过程,我们可以从deferproc的注释中简单了解这一过程:
func deferproc(siz int32, fn *funcval) {
// ...
// deferproc returns 0 normally.
// a deferred func that stops a panic
// makes the deferproc return 1.
// the code the compiler generates always
// checks the return value and jumps to the
// end of the function if deferproc returns != 0.
return0()
// No code can go here - the C return register has
// been set and must not be clobbered.
}
跳转到deferreturn函数之后,程序其实就从panic的过程中跳出来恢复了正常的执行逻辑,而gorecover函数也从_panic结构体中取出了调用panic时传入的arg参数。
2.4. 总结
Go 语言中 panic 和 recover 的实现其实与 defer 关键字的联系非常紧密,而分析程序的恐慌和恢复过程也比较棘手,不是特别容易理解。在文章的最后我们还是简单总结一下具体的实现原理:
- 在编译过程中会将 panic 和 recover 分别转换成 gopanic 和 gorecover函数,同时将 defer 转换成 deferproc 函数并在调用 defer 的函数和方法末尾增加 deferreturn 的指令;
- 在运行过程中遇到 gopanic 方法时,会从当前 Goroutine 中取出 _defer 的链表并通过 reflectcall 调用用于收尾的函数;
- 如果在 reflectcall 调用时遇到了 gorecover 就会直接将当前的 _panic.recovered 标记成 true 并返回 panic 传入的参数(在这时 recover 就能够获取到 panic 的信息);
- 在这次调用结束之后,gopanic 会从 _defer 结构体中取出程序计数器 pc 和栈指针 sp 并调用 recovery 方法进行恢复;
- recovery 会根据传入的 pc 和 sp 跳转到 deferproc 函数;
- 编译器自动生成的代码会发现 deferproc 的返回值不为 0,这时就会直接跳到 deferreturn 函数中并恢复到正常的控制流程(依次执行剩余的 defer 并正常退出);
- 如果没有遇到 gorecover 就会依次遍历所有的 _defer 结构,并在最后调用 fatalpanic 中止程序、打印 panic 参数并返回错误码 2;
- 整个过程涉及了一些 Go 语言底层相关的知识并且发生了非常多的跳转,相关的源代码也不是特别的直接,阅读起来也比较晦涩,不过还是对我们理解 Go 语言的错误处理机制有着比较大的帮助。